

用于自动化国际化测试的伪本地化
伪本地化是一种强大的测试技术,它将您的源文本转换为伪语言,以便在实际翻译开始前识别国际化(i18n)问题。本指南向您展示如何使用 pseudo-l10n npm包自动化伪本地化测试。
什么是伪本地化?
伪本地化是将应用源文本转换为一种改变后的伪语言的过程,该语言模拟了UI在翻译后的表现。它帮助QA工程师和开发人员在开发周期的早期识别国际化问题。
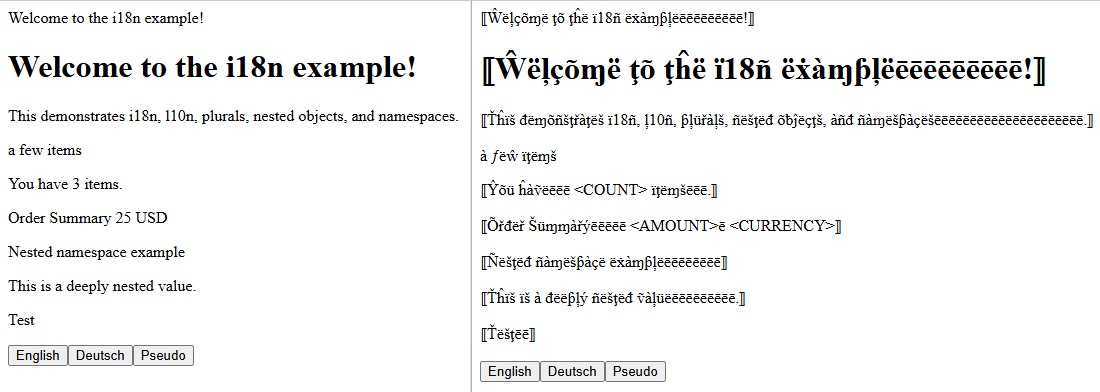
使用伪本地化识别潜在国际化问题的示例。两侧的字体和大小相同,但支持其他脚本通常需要更多空间。
为什么伪本地化很有用
伪本地化有助于您在早期捕获国际化问题:
- 暴露由文本扩展引起的布局损坏(德语和芬兰语通常比英语长30-40%)。
- 通过添加带重音的字符来测试UTF-8支持,从而发现编码问题。
- 确保所有字符串都是可翻译的 - 硬编码文本保持不变且易于发现。
- 揭示占位符处理不当 - 像{{name}}这样的动态内容必须被保留。
- 帮助定义具有空间限制的UI组件的翻译长度限制。
QA自动化策略
以下是使用伪本地化自动化国际化测试的成熟策略:
用带重音的形式或不同的脚本替换拉丁字母,以测试字符编码和字体支持。
示例: "Save" → "Šàvē"
QA检查: 确保所有字符显示正确,且不会因编码问题而导致任何内容损坏。
自动将每个字符串扩展约30–40%,以模拟德语或芬兰语等长语言。使用视觉标记包裹以方便检测截断。
示例: "Save" → ⟦Šàvēēēēē⟧
QA检查: 使用自动化截图对比来发现UI溢出、截断或对齐错误。
用可见标记替换插值变量(占位符),以验证它们在翻译过程中是否被保留。
示例: "You have {{count}} items" → "You have <COUNT> items"
QA检查: 运行回归测试;如果缺少标记或转义不正确(<COUNT>),则测试失败。
使用Unicode控制字符将文本包裹在从右到左(RTL)标记中,以模拟阿拉伯语或希伯来语。
QA检查: 验证RTL语言的对齐、文本方向和镜像是否正确。
将伪本地化添加到您的自动化测试管道中,以便在发布到生产环境之前捕获国际化问题。
QA检查: 如果测试检测到缺失的翻译、损坏的占位符或布局问题,则阻止部署。
使用pseudo-l10n包进行自动化
pseudo-l10n npm包可为您的JSON翻译文件自动化伪本地化,从而轻松将国际化测试集成到您的开发工作流程中。
- 文本扩展:模拟翻译文本通常比英语长30-40%的情况。
- 带重音字符:通过带重音的等效字符测试UTF-8编码和字体支持。
- 视觉标记:用⟦...⟧标记包裹字符串,以轻松发现未翻译或截断的文本。
- 占位符处理:保留{{name}}、{count}、%key%等占位符。
- 从右到左语言模拟:使用Unicode控制字符模拟从右到左的语言。
全局安装pseudo-l10n以供命令行使用:
npm install -g pseudo-l10n或将其添加为开发依赖项:
npm install --save-dev pseudo-l10n
将您的源翻译文件转换为伪本地化版本:
pseudo-l10n input.json output.json
输入 (en.json):
{
"welcome": "Welcome to our application",
"greeting": "Hello, {{name}}!",
"itemCount": "You have {{count}} items"
}输出 (pseudo-en.json):
{
"welcome": "⟦Ŵëļçõɱë ţõ õür àƥƥļïçàţïõñēēēēēēēēēēēēēēēēēē⟧",
"greeting": "⟦Ĥëļļõēēēēēē, {{name}}!ēēēēē⟧",
"itemCount": "⟦Ŷõü ĥàṽë {{count}} ïţëɱšēēēēēēēēēēēēēēēē⟧"
}
自定义扩展
pseudo-l10n en.json pseudo-en.json --expansion=30从右到左语言模拟
模拟阿拉伯语或希伯来语等从右到左的语言:
pseudo-l10n en.json pseudo-ar.json --rtl替换占位符以进行视觉测试
用大写标记替换占位符,以便于视觉检测:
pseudo-l10n en.json pseudo-en.json --replace-placeholders
# Input: { "greeting": "Hello, {{name}}!" }
# Output: { "greeting": "⟦Ĥëļļõēēēēēē, <NAME>!ēēēēē⟧" }支持不同的占位符格式
该包支持不同国际化库使用的各种占位符格式:
# For i18next (default)
pseudo-l10n en.json pseudo-en.json --placeholder-format="{{key}}"
# For Angular/React Intl
pseudo-l10n en.json pseudo-en.json --placeholder-format="{key}"
# For sprintf style
pseudo-l10n en.json pseudo-en.json --placeholder-format="%key%"
在您的Node.js脚本或构建过程中以编程方式使用pseudo-l10n:
const { generatePseudoLocaleSync, pseudoLocalize } = require('pseudo-l10n');
// Generate a pseudo-localized JSON file
generatePseudoLocaleSync('en.json', 'pseudo-en.json', {
expansion: 40,
rtl: false
});
// Pseudo-localize a single string
const result = pseudoLocalize('Hello, {{name}}!');
console.log(result);
// Output: ⟦Ĥëļļõēēēēēēēēēēēēēē, {{name}}!ēēēēē⟧集成到您的工作流程
将伪本地化生成添加到您的package.json脚本中:
{
"scripts": {
"pseudo": "pseudo-l10n src/locales/en.json src/locales/pseudo-en.json",
"pseudo:rtl": "pseudo-l10n src/locales/en.json src/locales/pseudo-ar.json --rtl"
}
}
将伪本地化语言环境生成作为构建过程的一部分:
// build.js
const { generatePseudoLocaleSync } = require('pseudo-l10n');
// Generate pseudo-locales as part of build
generatePseudoLocaleSync(
'./src/locales/en.json',
'./src/locales/pseudo-en.json',
{ expansion: 40 }
);
generatePseudoLocaleSync(
'./src/locales/en.json',
'./src/locales/pseudo-ar.json',
{ rtl: true }
);
将伪本地化集成到您的持续集成管道中:
# .github/workflows/test.yml
- name: Generate pseudo-locales
run: |
npm install -g pseudo-l10n
pseudo-l10n src/locales/en.json src/locales/pseudo-en.json
- name: Run i18n tests
run: npm run test:i18n测试策略
- 在构建过程中生成伪本地化语言环境。
- 将伪本地化语言环境添加到您的应用中(例如,在语言选择器中)。
- 在启用伪本地化语言环境的情况下测试您的应用。
- 审查应用是否存在常见的国际化问题。
- 缺少⟦⟧标记 = 未翻译的字符串(硬编码文本)。
- 标记被截断 = 文本截断或UI溢出。
- 布局损坏 = 文本扩展空间不足。
- 乱码 = 编码问题或缺少字体支持。
- 文本方向错误 = 从右到左语言问题(针对从右到左的伪本地化语言环境)。
从测试到真实翻译
一旦您通过伪本地化验证了国际化实现,就该为真实用户翻译您的应用了。这时就需要像l10n.dev这样的AI驱动翻译服务。
在确保您的应用通过伪本地化正确处理国际化后,使用l10n.dev进行专业的AI驱动翻译:
- 保留占位符、格式和结构 - 就像伪本地化在测试期间保护的一样。
- 支持165种语言,具备上下文感知的AI翻译。
- 自动处理复数形式、插值和特殊字符。
- 通过API或npm包(ai-l10n)提供CI/CD集成,实现自动化工作流程。
- 提供VS Code扩展和Web UI,用于人工翻译和审校。
- 使用伪本地化测试您的国际化实现,以便尽早发现问题。
- 修复测试期间发现的任何用户界面布局、编码或插值问题。
- 使用l10n.dev翻译您已验证的源文件,以获得生产就绪的翻译。
准备好尽早发现国际化问题并简化您的本地化工作流程了吗?
伪本地化是一种必不可少的测试技术,可帮助您在国际化问题进入生产环境之前将其捕获。通过使用pseudo-l10n包自动化伪本地化测试,您可以确保您的应用程序真正为全球受众做好准备。
结合来自l10n.dev的AI驱动的本地化,您可以更快、更自信地构建稳健的多语言应用程序。