

Pseudo-Lokalisierung für automatisiertes i18n-Testing
Pseudo-Lokalisierung ist eine leistungsstarke Testtechnik, die Ihren Quelltext in eine fiktive Sprache umwandelt, um Internationalisierungsprobleme (i18n) vor Beginn der eigentlichen Übersetzung zu identifizieren. Dieser Leitfaden zeigt Ihnen, wie Sie Pseudo-Lokalisierungstests mit dem pseudo-l10n npm-Paket automatisieren.
Was ist Pseudo-Lokalisierung?
Pseudo-Lokalisierung ist der Prozess der Umwandlung des Quelltexts Ihrer Anwendung in eine veränderte, fiktive Sprache, die nachahmt, wie sich die Benutzeroberfläche nach der Übersetzung verhält. Sie hilft QA-Ingenieuren und Entwicklern, i18n-Probleme früh im Entwicklungszyklus zu identifizieren.
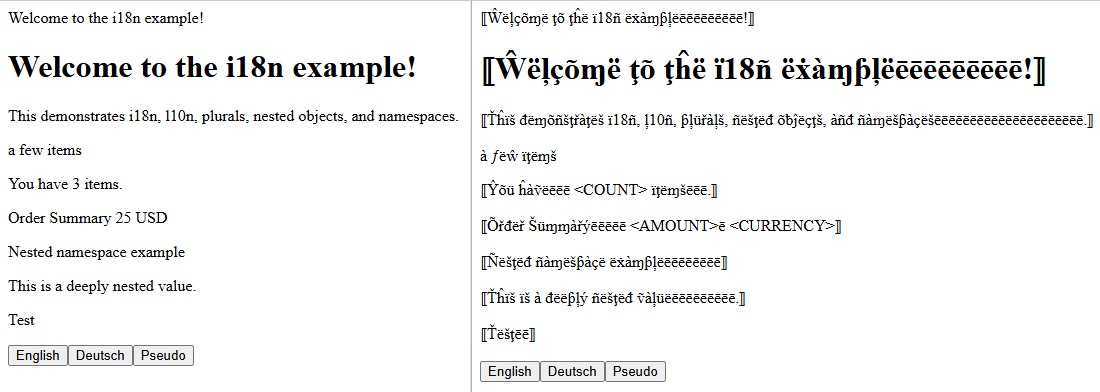
Beispiel für die Verwendung von Pseudo-Lokalisierung zur Identifizierung potenzieller Internationalisierungsprobleme. Die Schriftart und -größe sind auf beiden Seiten identisch, aber die Unterstützung anderer Skripte erfordert oft mehr Platz.
Warum Pseudo-Lokalisierung nützlich ist
Pseudo-Lokalisierung hilft Ihnen, i18n-Probleme frühzeitig zu erkennen:
- Deckt Layout-Brüche auf, die durch Texterweiterung verursacht werden (Deutsch und Finnisch sind typischerweise 30-40% länger als Englisch).
- Bringt Kodierungsprobleme durch Hinzufügen von Akzentzeichen zum Testen der UTF-8-Unterstützung an die Oberfläche.
- Stellt sicher, dass alle Strings übersetzbar sind – hartcodierter Text bleibt unverändert und ist leicht zu erkennen.
- Enthüllt den falschen Umgang mit Platzhaltern – dynamische Inhalte wie {{name}} müssen beibehalten werden.
- Hilft bei der Definition von Längenbegrenzungen für Übersetzungen bei UI-Komponenten mit Platzbeschränkungen.
Automatisierungsstrategien für QA
Hier sind bewährte Strategien zur Automatisierung von i18n-Tests mit Pseudo-Lokalisierung:
Ersetzen Sie lateinische Buchstaben durch akzentuierte Formen oder andere Skripte, um die Zeichenkodierung und Schriftunterstützung zu testen.
Beispiel: "Save" → "Šàvē"
QA-Check: Stellen Sie sicher, dass alle Zeichen korrekt angezeigt werden und nichts aufgrund von Kodierungsproblemen bricht.
Erweitern Sie jeden String automatisch um ca. 30–40%, um lange Sprachen wie Deutsch oder Finnisch nachzuahmen. Umschließen Sie sie mit visuellen Markierungen für eine einfache Erkennung von Clipping.
Beispiel: "Save" → ⟦Šàvēēēēē⟧
QA-Check: Verwenden Sie automatisierten Screenshot-Vergleich, um UI-Überläufe, Clipping oder Fehlausrichtungen zu erkennen.
Ersetzen Sie Interpolationsvariablen (Platzhalter) durch sichtbare Markierungen, um zu überprüfen, ob sie während der Übersetzung beibehalten werden.
Beispiel: "You have {{count}} items" → "You have <COUNT> items"
QA-Check: Führen Sie Regressionstests durch; schlagen Sie fehl, wenn eine Markierung fehlt oder falsch maskiert ist (<COUNT>).
Umschließen Sie Text mit Rechts-nach-Links-Markierungen (RTL) unter Verwendung von Unicode-Steuerzeichen, um Arabisch oder Hebräisch zu simulieren.
QA-Check: Überprüfen Sie, ob Ausrichtung, Textrichtung und Spiegelung für RTL-Sprachen korrekt sind.
Fügen Sie Pseudo-Lokalisierung zu Ihrer automatisierten Test-Pipeline hinzu, um i18n-Probleme zu erkennen, bevor sie die Produktion erreichen.
QA-Check: Blockieren Sie die Bereitstellung, wenn Tests fehlende Übersetzungen, defekte Platzhalter oder Layoutprobleme erkennen.
Automatisierung mit dem pseudo-l10n-Paket
Das npm-Paket pseudo-l10n automatisiert die Pseudo-Lokalisierung für Ihre JSON-Übersetzungsdateien und erleichtert die Integration von i18n-Tests in Ihren Entwicklungsworkflow.
- Texterweiterung: Simuliert, wie übersetzter Text oft 30-40% länger ist als Englisch.
- Akzentuierte Zeichen: Testet UTF-8-Kodierung und Schriftunterstützung mit akzentuierten Äquivalenten.
- Visuelle Markierungen: Umschließt Strings mit ⟦...⟧-Markierungen, um nicht übersetzten oder abgeschnittenen Text leicht zu erkennen.
- Platzhalterbehandlung: Behält Platzhalter wie {{name}}, {count}, %key% usw. bei.
- RTL-Simulation: Simuliert Rechts-nach-Links-Sprachen unter Verwendung von Unicode-Steuerzeichen.
Installieren Sie pseudo-l10n global für die Verwendung über die Befehlszeile:
npm install -g pseudo-l10nOder fügen Sie es als Entwicklungsabhängigkeit hinzu:
npm install --save-dev pseudo-l10n
Transformieren Sie Ihre Quell-Übersetzungsdatei in eine pseudo-lokalisierte Version:
pseudo-l10n input.json output.json
Eingabe (en.json):
{
"welcome": "Welcome to our application",
"greeting": "Hello, {{name}}!",
"itemCount": "You have {{count}} items"
}Ausgabe (pseudo-en.json):
{
"welcome": "⟦Ŵëļçõɱë ţõ õür àƥƥļïçàţïõñēēēēēēēēēēēēēēēēēē⟧",
"greeting": "⟦Ĥëļļõēēēēēē, {{name}}!ēēēēē⟧",
"itemCount": "⟦Ŷõü ĥàṽë {{count}} ïţëɱšēēēēēēēēēēēēēēēē⟧"
}
Benutzerdefinierte Erweiterung
pseudo-l10n en.json pseudo-en.json --expansion=30RTL-Simulation
Simulieren Sie Rechts-nach-Links-Sprachen wie Arabisch oder Hebräisch:
pseudo-l10n en.json pseudo-ar.json --rtlPlatzhalter für visuelle Tests ersetzen
Ersetzen Sie Platzhalter durch Großbuchstaben-Markierungen für eine einfachere visuelle Erkennung:
pseudo-l10n en.json pseudo-en.json --replace-placeholders
# Input: { "greeting": "Hello, {{name}}!" }
# Output: { "greeting": "⟦Ĥëļļõēēēēēē, <NAME>!ēēēēē⟧" }Unterstützung für verschiedene Platzhalterformate
Das Paket unterstützt verschiedene Platzhalterformate, die von unterschiedlichen i18n-Bibliotheken verwendet werden:
# For i18next (default)
pseudo-l10n en.json pseudo-en.json --placeholder-format="{{key}}"
# For Angular/React Intl
pseudo-l10n en.json pseudo-en.json --placeholder-format="{key}"
# For sprintf style
pseudo-l10n en.json pseudo-en.json --placeholder-format="%key%"
Verwenden Sie pseudo-l10n programmgesteuert in Ihren Node.js-Skripten oder Ihrem Build-Prozess:
const { generatePseudoLocaleSync, pseudoLocalize } = require('pseudo-l10n');
// Generate a pseudo-localized JSON file
generatePseudoLocaleSync('en.json', 'pseudo-en.json', {
expansion: 40,
rtl: false
});
// Pseudo-localize a single string
const result = pseudoLocalize('Hello, {{name}}!');
console.log(result);
// Output: ⟦Ĥëļļõēēēēēēēēēēēēēē, {{name}}!ēēēēē⟧Integration in Ihren Workflow
Fügen Sie die Generierung der Pseudo-Lokalisierung zu Ihren package.json-Skripten hinzu:
{
"scripts": {
"pseudo": "pseudo-l10n src/locales/en.json src/locales/pseudo-en.json",
"pseudo:rtl": "pseudo-l10n src/locales/en.json src/locales/pseudo-ar.json --rtl"
}
}
Generieren Sie Pseudo-Sprachversionen als Teil Ihres Build-Prozesses:
// build.js
const { generatePseudoLocaleSync } = require('pseudo-l10n');
// Generate pseudo-locales as part of build
generatePseudoLocaleSync(
'./src/locales/en.json',
'./src/locales/pseudo-en.json',
{ expansion: 40 }
);
generatePseudoLocaleSync(
'./src/locales/en.json',
'./src/locales/pseudo-ar.json',
{ rtl: true }
);
Integrieren Sie die Pseudo-Lokalisierung in Ihre Continuous-Integration-Pipeline:
# .github/workflows/test.yml
- name: Generate pseudo-locales
run: |
npm install -g pseudo-l10n
pseudo-l10n src/locales/en.json src/locales/pseudo-en.json
- name: Run i18n tests
run: npm run test:i18nTeststrategie
- Generieren Sie die Pseudo-Sprachversion während Ihres Build-Prozesses.
- Fügen Sie die Pseudo-Sprachversion zu Ihrer Anwendung hinzu (z. B. im Sprachauswähler).
- Testen Sie Ihre Anwendung mit aktivierter Pseudo-Sprachversion.
- Überprüfen Sie die Anwendung auf häufige i18n-Probleme.
- Fehlende ⟦⟧-Markierungen = nicht übersetzte Strings (hartcodierter Text).
- Abgeschnittene Markierungen = Textkürzung oder UI-Überlauf.
- Defektes Layout = unzureichender Platz für Texterweiterung.
- Verstümmelter Text = Kodierungsprobleme oder fehlende Schriftunterstützung.
- Falsche Textrichtung = RTL-Probleme (für RTL-Pseudo-Sprachversionen).
Vom Testen zur echten Übersetzung
Sobald Sie Ihre i18n-Implementierung mit Pseudo-Lokalisierung validiert haben, ist es an der Zeit, Ihre Anwendung für echte Benutzer zu übersetzen. Hier kommen KI-gestützte Übersetzungsdienste wie l10n.dev ins Spiel.
Nachdem Sie sichergestellt haben, dass Ihre App die Internationalisierung korrekt mit Pseudo-Lokalisierung handhabt, verwenden Sie l10n.dev für professionelle KI-gestützte Übersetzung:
- Bewahrt Platzhalter, Format und Struktur – genau wie pseudo-l10n während des Testens schützt.
- Unterstützt 165 Sprachen mit kontextbewusster KI-Übersetzung.
- Handhabt Pluralformen, Interpolation und Sonderzeichen automatisch.
- Bietet CI/CD-Integration über API oder npm-Paket (ai-l10n) für automatisierte Workflows.
- Bietet VS Code-Erweiterung und Web-UI für manuelle Übersetzung und Überprüfung.
- Testen Sie Ihre i18n-Implementierung mit Pseudo-Lokalisierung, um Probleme frühzeitig zu erkennen.
- Beheben Sie Layout-, Kodierungs- oder Platzhalterprobleme, die während des Tests entdeckt wurden.
- Übersetzen Sie Ihre validierten Quelldateien mit l10n.dev für produktionsreife Übersetzungen.
Bereit, i18n-Probleme frühzeitig zu erkennen und Ihren Lokalisierungsworkflow zu optimieren?
Laden Sie Ihre i18n-Dateien hoch und lassen Sie die KI die Übersetzung mit Kontextbewusstsein und korrekter Formatierung übernehmen
Entdecken Sie, warum KI-gestützte Lokalisierung für i18n-Dateien besser ist als herkömmliche Methoden
Integrieren Sie KI-gestützte Lokalisierung direkt in Ihre CI/CD-Pipeline
Bringen Sie KI-Lokalisierung mit unseren Erweiterungen und Plugins in Ihren Lokalisierungsworkflow
Pseudo-Lokalisierung ist eine wesentliche Testtechnik, die Ihnen hilft, Internationalisierungsprobleme zu erkennen, bevor sie die Produktion erreichen. Durch die Automatisierung von Pseudo-Lokalisierungstests mit dem pseudo-l10n-Paket können Sie sicherstellen, dass Ihre Anwendung wirklich bereit für ein globales Publikum ist.
In Kombination mit der KI-gestützten Übersetzung von l10n.dev können Sie robuste, mehrsprachige Anwendungen schneller und mit Zuversicht erstellen.