

用於自動化 i18n 測試的偽本地化
偽本地化是一種強大的測試技術,可將您的原始文字轉換為假語言,以便在實際翻譯開始前識別國際化 (i18n) 問題。本指南將向您展示如何使用 pseudo-l10n npm 套件來自動化偽本地化測試。
什麼是偽本地化?
偽本地化是將應用程式的原始文字轉換為一種模擬翻譯後 UI 行為的假語言的過程。它有助於 QA 工程師和開發者在開發週期的早期識別 i18n 問題。
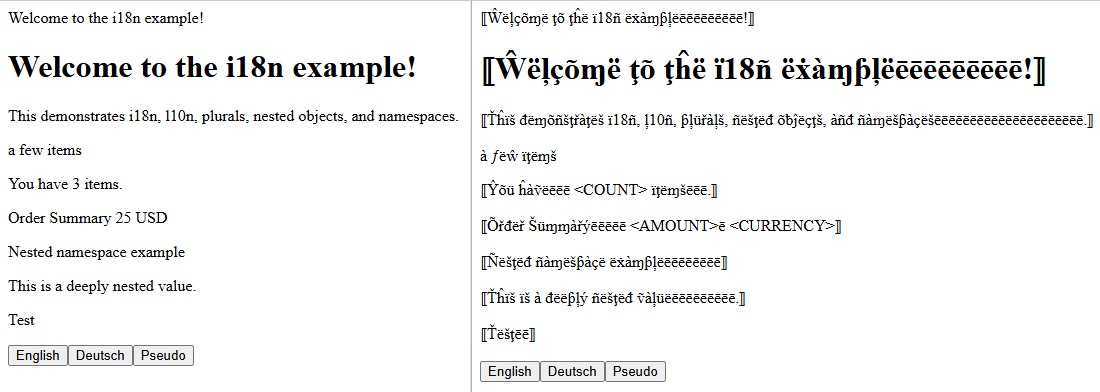
使用偽本地化識別潛在國際化問題的範例。兩側的字體和大小相同,但支援其他語言腳本通常需要更多空間。
為什麼偽本地化很有用
偽本地化有助於您儘早捕獲 i18n 問題:
- 暴露因文字擴充導致的佈局損壞(德語和芬蘭語通常比英語長 30-40%)。
- 透過新增重音字元來測試 UTF-8 支援,從而表面化編碼問題。
- 確保所有字串皆可翻譯 - 硬編碼文字保持不變且易於識別。
- 揭示佔位符處理不當 - 如 {{name}} 等動態內容必須被保留。
- 協助為有空間限制的 UI 元件定義翻譯長度限制。
QA 自動化策略
以下是使用偽本地化進行自動化 i18n 測試的成熟策略:
將拉丁字母替換為重音形式或不同腳本,以測試字元編碼和字體支援。
範例: "Save" → "Šàvē"
QA 檢查: 確保所有字元顯示正確,且不會因編碼問題而導致損壞。
自動將每個字串擴充約 30–40%,以模擬德語或芬蘭語等長語言。使用視覺標記包裹以便於偵測截斷。
範例: "Save" → ⟦Šàvēēēēē⟧
QA 檢查: 使用自動化螢幕截圖比較來發現 UI 溢出、截斷或對齊錯誤。
將插值變數(佔位符)替換為可見標記,以驗證它們在翻譯過程中是否被保留。
範例: "You have {{count}} items" → "You have <COUNT> items"
QA 檢查: 執行回歸測試;若標記缺失或轉義錯誤 (<COUNT>),則測試失敗。
使用 Unicode 控制字元將文字包裹在由右到左 (RTL) 標記中,以模擬阿拉伯語或希伯來語。
QA 檢查: 驗證 RTL 語言的對齊、文字方向和鏡像是否正確。
將偽本地化加入您的自動化測試流程中,以便在產品發布前捕獲 i18n 問題。
QA 檢查: 若測試偵測到缺失翻譯、損壞的佔位符或佈局問題,則阻擋部署。
使用 pseudo-l10n 套件進行自動化
pseudo-l10n npm 套件可自動化您的 JSON 翻譯檔案的偽本地化,讓您輕鬆將 i18n 測試整合到開發工作流程中。
- 文字擴充:模擬翻譯後的文字通常比英語長 30-40% 的情況。
- 重音字元:使用重音等效字元測試 UTF-8 編碼和字體支援。
- 視覺標記:使用 ⟦...⟧ 標記包裹字串,輕鬆發現未翻譯或截斷的文字。
- 佔位符處理:保留如 {{name}}、{count}、%key% 等佔位符。
- RTL 模擬:使用 Unicode 控制字元模擬由右到左語言。
全域安裝 pseudo-l10n 以進行命令列使用:
npm install -g pseudo-l10n或將其作為開發依賴項新增:
npm install --save-dev pseudo-l10n
將您的原始翻譯檔案轉換為偽本地化版本:
pseudo-l10n input.json output.json
輸入 (en.json):
{
"welcome": "Welcome to our application",
"greeting": "Hello, {{name}}!",
"itemCount": "You have {{count}} items"
}輸出 (pseudo-en.json):
{
"welcome": "⟦Ŵëļçõɱë ţõ õür àƥƥļïçàţïõñēēēēēēēēēēēēēēēēēē⟧",
"greeting": "⟦Ĥëļļõēēēēēē, {{name}}!ēēēēē⟧",
"itemCount": "⟦Ŷõü ĥàṽë {{count}} ïţëɱšēēēēēēēēēēēēēēēē⟧"
}
自訂擴充
pseudo-l10n en.json pseudo-en.json --expansion=30RTL 模擬
模擬阿拉伯語或希伯來語等由右到左語言:
pseudo-l10n en.json pseudo-ar.json --rtl替換佔位符以進行視覺測試
將佔位符替換為大寫標記,以便於視覺偵測:
pseudo-l10n en.json pseudo-en.json --replace-placeholders
# Input: { "greeting": "Hello, {{name}}!" }
# Output: { "greeting": "⟦Ĥëļļõēēēēēē, <NAME>!ēēēēē⟧" }支援不同佔位符格式
該套件支援不同 i18n 函式庫使用的各種佔位符格式:
# For i18next (default)
pseudo-l10n en.json pseudo-en.json --placeholder-format="{{key}}"
# For Angular/React Intl
pseudo-l10n en.json pseudo-en.json --placeholder-format="{key}"
# For sprintf style
pseudo-l10n en.json pseudo-en.json --placeholder-format="%key%"
在您的 Node.js 腳本或建置流程中以程式化方式使用 pseudo-l10n:
const { generatePseudoLocaleSync, pseudoLocalize } = require('pseudo-l10n');
// Generate a pseudo-localized JSON file
generatePseudoLocaleSync('en.json', 'pseudo-en.json', {
expansion: 40,
rtl: false
});
// Pseudo-localize a single string
const result = pseudoLocalize('Hello, {{name}}!');
console.log(result);
// Output: ⟦Ĥëļļõēēēēēēēēēēēēēē, {{name}}!ēēēēē⟧整合到您的工作流程
將偽本地化產生加入您的 package.json 腳本:
{
"scripts": {
"pseudo": "pseudo-l10n src/locales/en.json src/locales/pseudo-en.json",
"pseudo:rtl": "pseudo-l10n src/locales/en.json src/locales/pseudo-ar.json --rtl"
}
}
將偽語系產生作為建置流程的一部分:
// build.js
const { generatePseudoLocaleSync } = require('pseudo-l10n');
// Generate pseudo-locales as part of build
generatePseudoLocaleSync(
'./src/locales/en.json',
'./src/locales/pseudo-en.json',
{ expansion: 40 }
);
generatePseudoLocaleSync(
'./src/locales/en.json',
'./src/locales/pseudo-ar.json',
{ rtl: true }
);
將偽本地化整合到您的持續整合流水線中:
# .github/workflows/test.yml
- name: Generate pseudo-locales
run: |
npm install -g pseudo-l10n
pseudo-l10n src/locales/en.json src/locales/pseudo-en.json
- name: Run i18n tests
run: npm run test:i18n測試策略
- 在建置流程中產生偽語系。
- 將偽語系新增至您的應用程式(例如在語言選擇器中)。
- 啟用偽語系來測試您的應用程式。
- 檢查應用程式是否存在常見的 i18n 問題。
- 缺失 ⟦⟧ 標記 = 未翻譯的字串(硬編碼文字)。
- 標記被截斷 = 文字截斷或 UI 溢出。
- 佈局損壞 = 文字擴充空間不足。
- 亂碼 = 編碼問題或缺少字體支援。
- 文字方向錯誤 = RTL 問題(針對 RTL 偽語系)。
從測試到實際翻譯
一旦您使用偽本地化驗證了 i18n 實作,就該為真實使用者翻譯您的應用程式了。這就是像 l10n.dev 這樣的 AI 驅動翻譯服務發揮作用的時候。
在確保您的應用程式透過偽本地化正確處理國際化後,請使用 l10n.dev 進行專業的 AI 驅動翻譯:
- 保留佔位符、格式和結構 - 就像 pseudo-l10n 在測試期間所保護的那樣。
- 支援 165 種語言的語境感知 AI 翻譯。
- 自動處理複數形式、插值和特殊字元。
- 透過 API 或 npm 封裝 (ai-l10n) 提供 CI/CD 整合,以實現自動化工作流程。
- 提供 VS Code 擴充功能和網頁 UI,用於手動翻譯與審核。
- 使用偽本地化測試您的 i18n 實作,以便儘早發現問題。
- 修復測試期間發現的任何佈局、字元編碼或佔位符問題。
- 使用 l10n.dev 翻譯您已驗證的原文語言檔案,以獲得生產級的翻譯。
準備好儘早發現 i18n 問題並簡化您的本地化工作流程了嗎?
偽本地化是一種必要的測試技術,可協助您在進入生產環境前發現國際化問題。透過使用 pseudo-l10n 封裝進行偽本地化測試自動化,您可以確保您的應用程式真正為全球用戶做好準備。
結合來自 l10n.dev 的 AI 翻譯,您可以更快且更有信心地建構穩健的多語言應用程式。