

Pseudo-localisation pour les tests i18n automatisés
La pseudo-localisation est une technique de test puissante qui transforme votre texte source en une fausse langue pour identifier les problèmes de localisation (i18n) avant que la traduction réelle ne commence. Ce guide vous montre comment automatiser les tests de pseudo-localisation en utilisant le package npm pseudo-l10n.
Qu'est-ce que la pseudo-localisation ?
La pseudo-localisation est le processus de transformation du texte source de votre application en une fausse langue altérée qui imite le comportement de l'interface utilisateur après la traduction. Elle aide les ingénieurs QA et les développeurs à identifier les problèmes d'i18n tôt dans le cycle de développement.
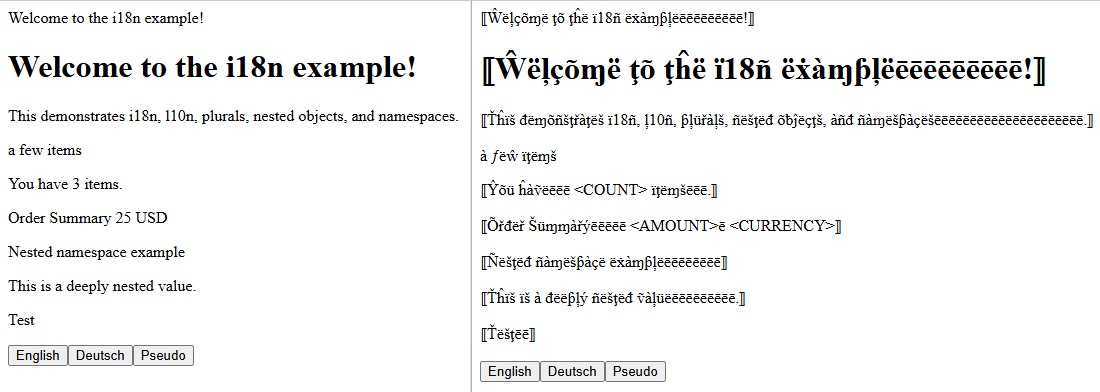
Exemple d'utilisation de la pseudo-localisation pour identifier des problèmes de localisation potentiels. La police et la taille sont identiques des deux côtés, mais la prise en charge d'autres scripts nécessite souvent plus d'espace.
Pourquoi la pseudo-localisation est utile
La pseudo-localisation vous aide à détecter les problèmes d'i18n tôt :
- Expose les ruptures de mise en page causées par l'expansion du texte (l'allemand et le finnois sont généralement 30 à 40 % plus longs que l'anglais).
- Fait apparaître les problèmes d'encodage en ajoutant des caractères accentués pour tester la prise en charge UTF-8.
- Garantit que toutes les chaînes sont traduisibles - le texte codé en dur reste inchangé et est facile à repérer.
- Révèle une mauvaise gestion des espaces réservés - le contenu dynamique comme {{name}} doit être préservé.
- Aide à définir les limites de longueur de traduction pour les composants d'interface utilisateur avec des contraintes d'espace.
Stratégies d'automatisation pour la QA
Voici des stratégies éprouvées pour automatiser les tests i18n avec la pseudo-localisation :
Remplacez les lettres latines par des formes accentuées ou des scripts différents pour tester l'encodage des caractères et la prise en charge des polices.
Exemple : "Save" → "Šàvē"
Vérification QA : Assurez-vous que tous les caractères s'affichent correctement et que rien ne se casse en raison de problèmes d'encodage.
Développez automatiquement chaque chaîne d'environ 30 à 40 % pour imiter les langues longues comme l'allemand ou le finnois. Enveloppez avec des marqueurs visuels pour une détection facile du découpage.
Exemple : "Save" → ⟦Šàvēēēēē⟧
Vérification QA : Utilisez la comparaison automatisée de captures d'écran pour repérer le débordement, le découpage ou le mauvais alignement de l'interface utilisateur.
Remplacez les variables d'interpolation (espaces réservés) par des marqueurs visibles pour vérifier qu'ils sont préservés pendant la traduction.
Exemple : "You have {{count}} items" → "You have <COUNT> items"
Vérification QA : Exécutez des tests de régression ; échouez si un marqueur est manquant ou incorrectement échappé (<COUNT>).
Enveloppez le texte dans des marqueurs de droite à gauche (RTL) en utilisant des caractères de contrôle Unicode pour simuler l'arabe ou l'hébreu.
Vérification QA : Vérifiez que l'alignement, la direction du texte et la mise en miroir sont corrects pour les langues RTL.
Ajoutez la pseudo-localisation à votre pipeline de tests automatisés pour détecter les problèmes d'i18n avant qu'ils n'atteignent la production.
Vérification QA : Bloquez le déploiement si les tests détectent des traductions manquantes, des espaces réservés cassés ou des problèmes de mise en page.
Automatisation avec le package pseudo-l10n
Le package npm pseudo-l10n automatise la pseudo-localisation pour vos fichiers de traduction JSON, facilitant l'intégration des tests i18n dans votre flux de travail de développement.
- Expansion du texte : Simule comment le texte traduit est souvent 30 à 40 % plus long que l'anglais.
- Caractères accentués : Teste l'encodage UTF-8 et la prise en charge des polices avec des équivalents accentués.
- Marqueurs visuels : Enveloppe les chaînes avec des marqueurs ⟦...⟧ pour repérer facilement le texte non traduit ou tronqué.
- Gestion des espaces réservés : Préserve les espaces réservés comme {{name}}, {count}, %key%, etc.
- Simulation RTL : Simule les langues de droite à gauche en utilisant des caractères de contrôle Unicode.
Installez pseudo-l10n globalement pour une utilisation en ligne de commande :
npm install -g pseudo-l10nOu ajoutez-le en tant que dépendance de développement :
npm install --save-dev pseudo-l10n
Transformez votre fichier de traduction source en une version pseudo-localisée :
pseudo-l10n input.json output.json
Entrée (en.json) :
{
"welcome": "Welcome to our application",
"greeting": "Hello, {{name}}!",
"itemCount": "You have {{count}} items"
}Sortie (pseudo-en.json) :
{
"welcome": "⟦Ŵëļçõɱë ţõ õür àƥƥļïçàţïõñēēēēēēēēēēēēēēēēēē⟧",
"greeting": "⟦Ĥëļļõēēēēēē, {{name}}!ēēēēē⟧",
"itemCount": "⟦Ŷõü ĥàṽë {{count}} ïţëɱšēēēēēēēēēēēēēēēē⟧"
}
Expansion personnalisée
pseudo-l10n en.json pseudo-en.json --expansion=30Simulation RTL
Simulez des langues de droite à gauche comme l'arabe ou l'hébreu :
pseudo-l10n en.json pseudo-ar.json --rtlRemplacer les espaces réservés pour les tests visuels
Remplacez les espaces réservés par des marqueurs en majuscules pour une détection visuelle plus facile :
pseudo-l10n en.json pseudo-en.json --replace-placeholders
# Input: { "greeting": "Hello, {{name}}!" }
# Output: { "greeting": "⟦Ĥëļļõēēēēēē, <NAME>!ēēēēē⟧" }Prise en charge de différents formats d'espaces réservés
Le package prend en charge divers formats d'espaces réservés utilisés par différentes bibliothèques i18n :
# For i18next (default)
pseudo-l10n en.json pseudo-en.json --placeholder-format="{{key}}"
# For Angular/React Intl
pseudo-l10n en.json pseudo-en.json --placeholder-format="{key}"
# For sprintf style
pseudo-l10n en.json pseudo-en.json --placeholder-format="%key%"
Utilisez pseudo-l10n par programmation dans vos scripts Node.js ou votre processus de build :
const { generatePseudoLocaleSync, pseudoLocalize } = require('pseudo-l10n');
// Generate a pseudo-localized JSON file
generatePseudoLocaleSync('en.json', 'pseudo-en.json', {
expansion: 40,
rtl: false
});
// Pseudo-localize a single string
const result = pseudoLocalize('Hello, {{name}}!');
console.log(result);
// Output: ⟦Ĥëļļõēēēēēēēēēēēēēē, {{name}}!ēēēēē⟧Intégration dans votre flux de travail
Ajoutez la génération de pseudo-localisation à vos scripts package.json :
{
"scripts": {
"pseudo": "pseudo-l10n src/locales/en.json src/locales/pseudo-en.json",
"pseudo:rtl": "pseudo-l10n src/locales/en.json src/locales/pseudo-ar.json --rtl"
}
}
Générez des pseudo-locales dans le cadre de votre processus de build :
// build.js
const { generatePseudoLocaleSync } = require('pseudo-l10n');
// Generate pseudo-locales as part of build
generatePseudoLocaleSync(
'./src/locales/en.json',
'./src/locales/pseudo-en.json',
{ expansion: 40 }
);
generatePseudoLocaleSync(
'./src/locales/en.json',
'./src/locales/pseudo-ar.json',
{ rtl: true }
);
Intégrez la pseudo-localisation dans votre pipeline d'intégration continue :
# .github/workflows/test.yml
- name: Generate pseudo-locales
run: |
npm install -g pseudo-l10n
pseudo-l10n src/locales/en.json src/locales/pseudo-en.json
- name: Run i18n tests
run: npm run test:i18nStratégie de test
- Générez une pseudo-locale pendant votre processus de build.
- Ajoutez la pseudo-locale à votre application (par exemple, dans le sélecteur de langue).
- Testez votre application avec la pseudo-locale activée.
- Passez en revue l'application pour les problèmes d'i18n courants.
- Marqueurs ⟦⟧ manquants = chaînes non traduites (texte codé en dur).
- Marqueurs coupés = troncation de texte ou débordement de l'interface utilisateur.
- Mise en page cassée = espace insuffisant pour l'expansion du texte.
- Texte brouillé = problèmes d'encodage ou prise en charge des polices manquante.
- Mauvaise direction du texte = problèmes RTL (pour les pseudo-locales RTL).
De la phase de test à la traduction réelle
Une fois que vous avez validé votre implémentation i18n avec la pseudo-localisation, il est temps de traduire votre application pour de vrais utilisateurs. C'est là qu'interviennent les services de traduction assistée par IA comme l10n.dev.
Après vous être assuré que votre application gère correctement la localisation avec la pseudo-localisation, utilisez l10n.dev pour une traduction professionnelle assistée par IA :
- Préserve les espaces réservés, le format et la structure - tout comme la pseudo-l10n protège pendant les tests.
- Prend en charge 165 langues avec une traduction assistée par IA consciente du contexte.
- Gère automatiquement les formes plurielles, l'interpolation et les caractères spéciaux.
- Fournit une intégration CI/CD via une API ou un package npm (ai-l10n) pour des flux de travail automatisés.
- Propose une extension VS Code et une interface web pour la traduction et la révision manuelles.
- Testez votre implémentation i18n avec la pseudo-localisation pour détecter les problèmes rapidement.
- Corrigez tout problème de mise en page, d'encodage ou d'espaces réservés découvert lors des tests.
- Traduisez vos fichiers sources validés en utilisant l10n.dev pour des traductions prêtes pour la production.
Prêt à détecter les problèmes i18n rapidement et à rationaliser votre flux de travail de localisation ?
Téléversez vos fichiers i18n et laissez l'IA gérer la traduction avec une conscience du contexte et une préservation du format
Découvrez pourquoi la traduction assistée par IA est meilleure pour les fichiers i18n que les méthodes traditionnelles
Intégrez la localisation assistée par IA directement dans votre pipeline CI/CD
Intégrez la localisation assistée par IA dans votre flux de travail avec nos extensions et plugins
La pseudo-localisation est une technique de test essentielle qui vous aide à détecter les problèmes d'internationalisation avant qu'ils n'atteignent la production. En automatisant les tests de pseudo-localisation avec le package pseudo-l10n, vous pouvez vous assurer que votre application est réellement prête pour un public mondial.
Combiné à la traduction assistée par IA de l10n.dev, vous pouvez créer des applications multilingues robustes plus rapidement et en toute confiance.